Building your first experiment
Overview
This guide explains how to create your first experiment in LaunchDarkly. By the end, you’ll have a running experiment using a flag, an audience, and one or more metrics.
As you go through the process of creating your first experiment, you will be answering four questions:
- Implementation: Is your LaunchDarkly setup ready to run an experiment?
- Audience: Who are you experimenting on, and how do you target them?
- Metrics: What are you measuring, and where does that data come from?
- Experiment: How do you launch it?
Each step below corresponds to one of those questions. Some steps are for the engineer configuring LaunchDarkly, and others are for the experiment owner or product manager designing the test. Each section is labeled, so you can skim past the parts that aren’t yours.
If you already have flags and an SDK live in production, jump to Verify with live events to confirm it’s experiment-ready.
Try the LaunchDarkly sandbox
Use the LaunchDarkly demo sandbox to explore experimentation without setting up an SDK.
What you’ll need
Before you start, you’ll need:
- A LaunchDarkly account with an environment where you can create flags.
- An application or service where you can deploy SDK changes, or one that’s already connected to LaunchDarkly.
- At least one outcome you care about, such as a click, a signup, a transaction, or something else that is measurable.
For the full list of SDK version requirements, role permissions, and Relay Proxy configurations, read Experimentation prerequisites.
Step 1: Get LaunchDarkly running in your product
For engineers
This step gets you to a working baseline of an SDK installed, flag evaluations working, and events flowing back to LaunchDarkly. The rest of the quickstart depends on all three.
Already have an SDK installed?
Many LaunchDarkly customers already have an SDK in production. If that’s you, skip ahead to Verify with live events.
The quickest way to check is to open the live events page for your environment. If you see flag evaluation events flowing, you have a working SDK.
Pick the SDK appropriate for where you want to experiment
If you don’t have an SDK installed yet, choose one based on where the user behavior you want to experiment on happens.
Here’s what we recommend:
- Frontend/web: JavaScript, React Web
- Backend/server: Java, Node.js (server-side), Python, Go, .NET (server-side)
- Mobile: iOS, Android, React Native, Flutter
- Edge/serverless: Cloudflare, Vercel
For the full list, read SDKs.
You must enable event tracking
Experimentation requires the SDK to send events to LaunchDarkly. Some SDKs send events by default, while others require explicit configuration. To learn more, read SDK configuration.
Install and initialize the SDK
In LaunchDarkly, click the question mark in the left nav and select Install SDK to open the “Connect your app to LaunchDarkly” screen. Choose an SDK from the dropdown menu and follow the inline instructions.
The install and initialization snippets below are starter examples. Use the in-product Install SDK flow to get instructions with your real SDK key already populated.
Install the SDK
Here’s how to install select SDKs:
Initialize the SDK
Here’s how to initialize select SDKs:
Don't hardcode SDK keys in production
These snippets include inline SDK keys for clarity. In real applications, load keys from environment variables or a secrets manager.
Confirm your SDK setup
Before you go further, confirm your setup meets these requirements:
- Your code evaluates a feature flag using a variation method, such as
boolVariationorstringVariation. - Your code passes a context into that evaluation.
- The SDK sends flag evaluation events back to LaunchDarkly.
If any of these are missing, the rest of the quickstart won’t produce a working experiment.
Verify with live events
The fastest way to confirm all three are working is by using the live events page. Here’s how:
- In the left sidebar, click Code. The CodeControl menu appears.
- Click Live events.
- Click All events and select the Flags filter.
- Enter the flag key in the search bar to view only events related to your flag.
- Confirm that you see flag evaluation events for the flag you’ll experiment on.
- Confirm that the context kind and key match what your code is sending.
- If you’ve already called
track(), confirm your custom events appear here too.
If events aren’t appearing, the three most common causes are:
- Context kind mismatch: Your code passes one kind, often
user, but the project or flag targets a different kind. - SDK key from the wrong environment: Events are flowing, just into a different environment than the one you’re viewing.
- Wrong project: The SDK key belongs to a different LaunchDarkly project than the one you’re experimenting in.
Step 2: Define who you’re experimenting on
For engineers and experiment owners
The experiment owner designs the audience and the engineer confirms the SDK is sending the right attributes.
This step shows you how to use LaunchDarkly features including contexts, flag variations, and targeting rules to define who you are running an experiment on.
Contexts
A context is the “thing” an experiment treats as a single unit of randomization: usually a user, sometimes an account, organization, device, or session.
Every context has:
- A kind, for example,
user. - A key that uniquely identifies it, for example,
example-user-key. - Optional attributes you can target on, for example,
country,plan,email_domain.
For experiments, the context kind also determines the randomization unit. The randomization unit determines how your audience is assigned different variations. For example, To experiment on individual users, use a context kind of user. If instead you want everyone in the same organization sees the same variation, use a context kind of account, or whatever kind you call your organization-level.
The minimum the rest of this quickstart assumes that your code passes a context whose kind matches what you want to experiment on.
To learn more, read Contexts and Randomization units.
Flag variations
Every LaunchDarkly experiment uses a flag. The flag’s variations are the experiment’s treatments. Each variation corresponds to one version of the experience you want to compare.
If you don’t have a flag yet:
- In the left nav, click Create, then Flag.
- Choose a flag type:
- Boolean for an A/B test of the control versus a treatment.
- Multivariate for A/B/n tests of three or more treatments.
- Define the variations. Each variation is one treatment. For example,
controlandnew_checkout_flow. - Leave the default rule as-is for now. You’ll set targeting in the next section.
If you already have a flag controlling the feature you want to test, use it. Just confirm its variations match what you want to compare.
Flag targeting
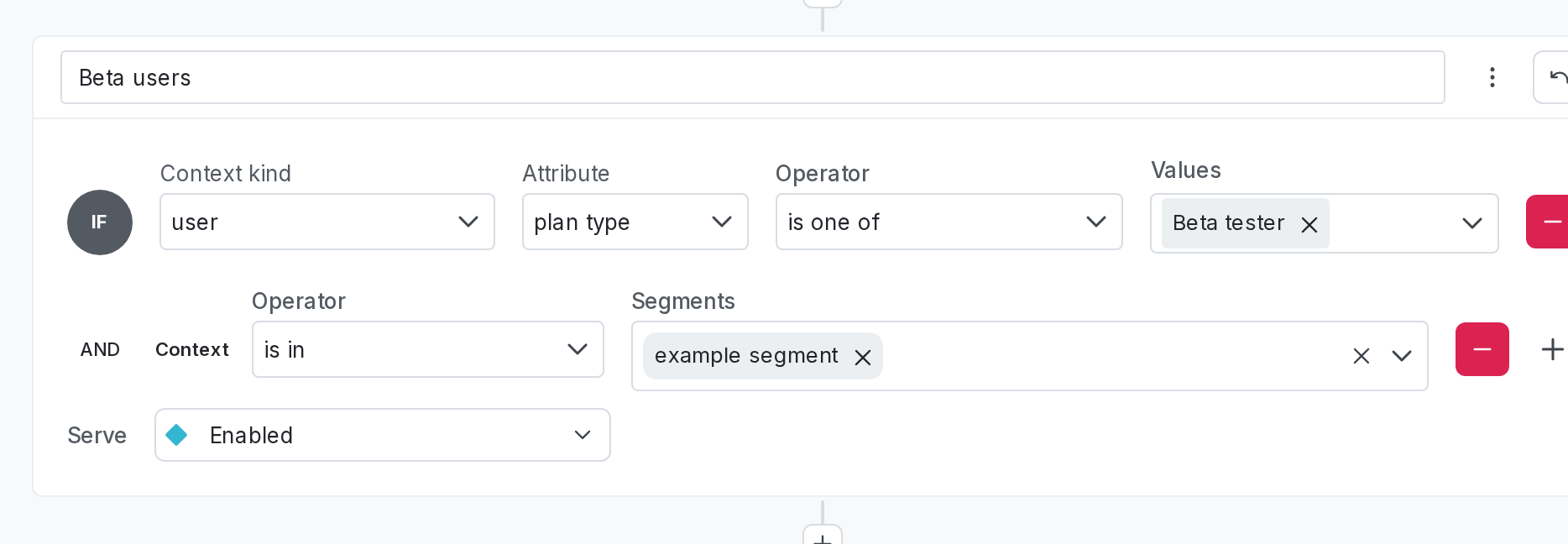
By default, an experiment samples from everyone the flag is toggled on for. The flag’s targeting rules define the experiment’s audience.
There are two ways to define the audience:
- Create a targeting rule specific for this test: for example,
country is US AND plan is paid. - Target a reusable audience segment: for example,
segment is beta users
Use a segment if the audience is reusable across multiple experiments or features. Otherwise, individual targeting rules are faster to set up.
Examples of audience targeting
Here are three common audience patterns:
- All logged-in users on web: Context kind
user, ruleis_authenticated is true AND platform is web. Run this when the change is universal but you want a clean web-only signal. - US users on a paid plan: Context kind
user, rulecountry is US AND plan is paid. Run this when the change targets a high-value segment and you want to protect free or non-US traffic from risk. - Free-plan accounts: Context kind
account, ruleplan is free. Run this when account-level effects matter more than per-user randomization — for example, when every user in an organization should see the same variation.
To learn more, read Target with flags.
Step 3: Choose what you’ll measure
For engineers and experiment owners
The experiment owner picks the metric, and the engineer or analytics team configures the SDK to send events.
This step shows you how to use LaunchDarkly metrics and verify that the data is flowing before you start. You can source your data directly from code with a track call, or you can connect to your external data warehouse, such as Snowflake.
Choose a metric type
Before you implement your code, decide what kind of measurement you need. The three most common types are:
- Occurrence (default for most cases): “Did this user do it at all?” Good for funnel-style metrics like signed-up, completed-checkout, or activated.
- Count: “How many times did this user do it?” Good for engagement metrics like page views or messages sent.
- Value / size: “What was the numeric value of this event?” Good for revenue, latency, or anything with a magnitude.
To learn more, read Choosing metrics.
Create your first metric
Creating a metric requires two steps:
- instrument the event in your code
- create the matching metric in the LaunchDarkly user interface (UI)
Instrument the event in your code
In your app, where the action happens, call track() with the event key. For example, this might be the checkout button click handler. Use the same context you pass to flag evaluation.
Here’s how:
Match the context to the randomization unit
The context you pass to track() should match the experiment’s randomization unit. If you randomize on user but track on account, the metric won’t attribute events correctly.
Verify the data is flowing
It’s tempting to skip this step, and expensive to skip. After you’ve shipped the track() change and triggered the action a few times in your app:
- Open the live events page.
- Find your event key in the list.
- Confirm the count is increasing.
- Confirm the context attached to the event matches the experiment’s randomization unit.
If you don’t see events, the most common causes are an SDK that is still initializing, an SDK key from the wrong environment, or a typo in the event key.
Don't start an experiment until you can see your metric event flowing
A metric that isn’t recording events will silently produce no signal. Verify on the lieve events page before launching.
Create the metric in LaunchDarkly
To create a new metric:
- Navigate to the Metrics list in LaunchDarkly by opening the Data section in the left nav, then clicking Metrics.
- Choose LaunchDarkly hosted. If you want to use warehouse native metrics, that’s a separate procedure.
- Enter the Event key, which is the exact string you passed to
track(). - Choose how you want to measure the event: Occurrence, Count, or Value / size.
- Give the metric a human-readable Name and description.
- Click Create metric.
To learn more, read Creating and managing metrics.
Primary and secondary metrics
When you set up the experiment in the next step, you’ll pick one primary metric and, optionally, a few secondary metrics.
- Primary metric: The primary metric is the one the experiment is trying to move. Statistical decisions center on this metric.
- Secondary metrics: Secondary metrics provide additional signal, but you shouldn’t make final decisions based on secondary metrics. Use secondary metrics to understand mechanisms, for example, “did checkout clicks go up because completion rates went up, or because more people opened checkout?”
A good default is one primary metric you most care about, plus one to three secondaries that explain how the primary moves.
Step 4: Create your experiment
For experiment owners
Now you have a flag, an audience, and a metric. This step walks through the LaunchDarkly experiment builder, calls out the small number of decisions you need to make, and tells you what to watch for in the first hours after launch.
Start from the flag targeting rule
If you already have a flag with targeting rules, open the flag, click the three-dot overflow menu for a rule, and select Create experiment from rule. The builder opens with the flag and its variations already attached.
Start from the builder
If you’d rather start from the builder open Experiments in the left nav, and click Create experiment.
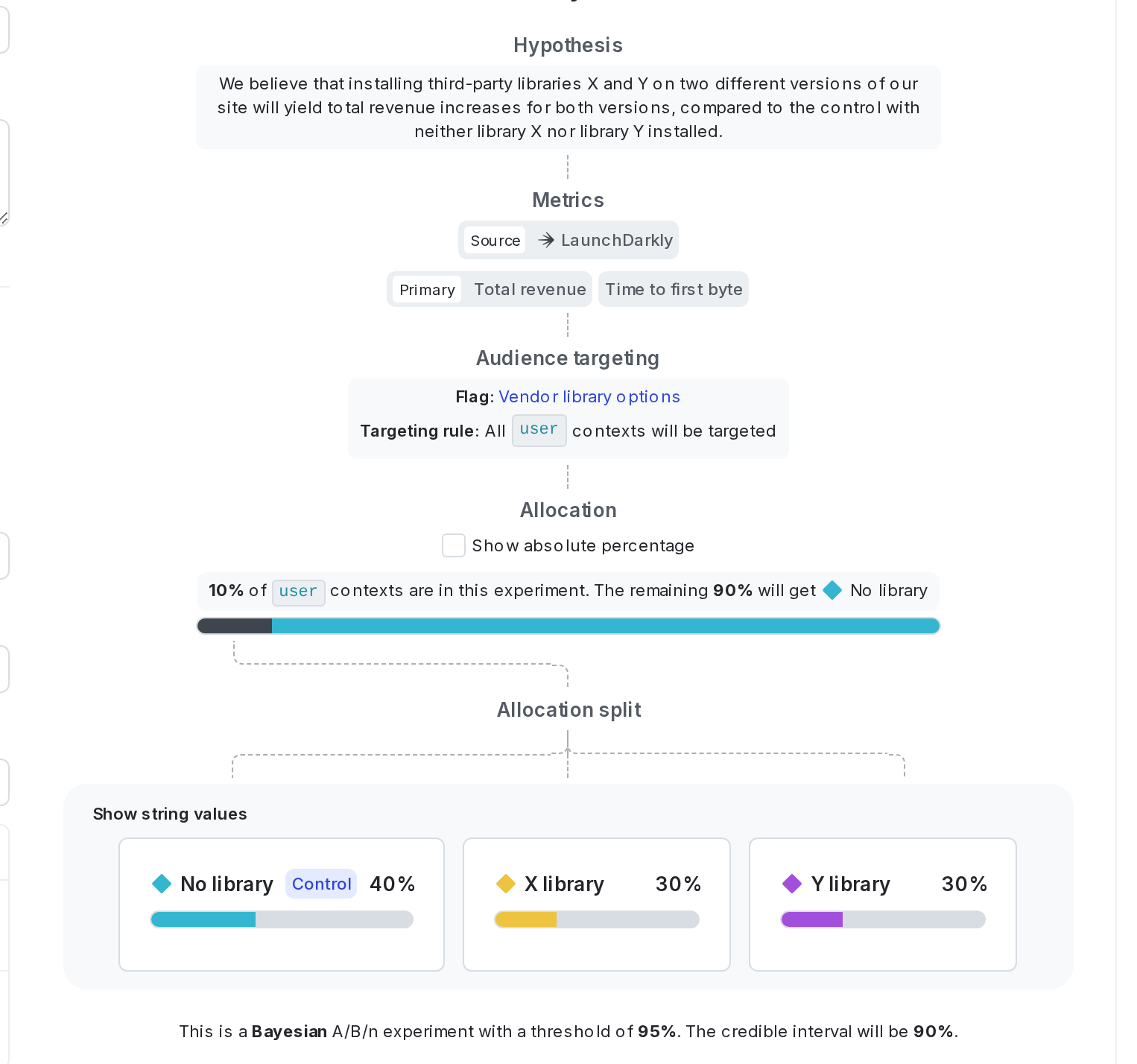
LaunchDarkly’s experiment builder breaks setup into discrete decisions:
- Hypothesis: A one- or two-sentence statement of what you expect to happen and why.
- Example: “We hypothesize that showing the new checkout flow will increase completion rate by three percentage points, because the redesigned form removes two friction points.”
- This is what you’ll come back to when interpreting results. Write it down even if it feels obvious. To learn more, read Designing experiments: formulate a hypothesis.
- Randomization unit: Usually
user. Whatever you pick must match the context kind your code passes and the metric’s unit. Mismatches here are the most common cause of broken experiments. To learn more, read Randomization units. - Audience: Which targeting rule from the flag is in the experiment. You can also choose a specific segment.
- Variations and traffic split: Which flag variations are in the experiment, and what percentage of the audience each gets. For a two-variation test, 50/50 gives the most statistical power per unit of time. Only skew the split if there’s a specific reason, for example, you want to limit exposure to a riskier treatment.
- Metrics: Pick the primary metric you defined in Step 3, and add any secondaries or guardrails. To learn more about traffic allocation across variations, read Experiment allocation.
- Statistical settings: Leave the defaults unless you have a specific reason to change them. The defaults pick a sensible analysis method, significance threshold, and minimum sample size estimate.
To learn more about each builder step, read Creating experiments.
Use the builder defaults
Most experiments don’t need bespoke statistical settings. The decisions that matter for your first experiment are fewer than you might think.
Safe to leave on default:
- Statistical method
- Significance threshold
- Sequential testing / peek protection (leave on)
Decisions you need to make:
- The hypothesis: write it down.
- The randomization unit: must match the context kind in code and the metric’s unit. Usually
user. - The primary metric: exactly one.
- The audience: the targeting rule that defines who’s in the experiment.
- The traffic split: default 50/50 is usually fine.
Checklist before you start the experiment
Before clicking Start, review this checklist:
- The flag’s targeting matches the audience you intended.
- The metric event is currently flowing on the live events page.
- The variations are the ones you want to compare.
- The randomization unit matches the context kind your code is passing.
By viewing the draft of the experiment before you start it, you can verify that all of these steps are complete:
Start the experiment and monitor
From the experiment’s design tab, click Start. Then:
- In the first few hours: Watch for an SRM warning. If LaunchDarkly flags one, stop, fix the cause, and restart. To learn more, read Experiment health checks.
- In the first day: Confirm both variations are receiving traffic in roughly the proportion you set.
- In the first week and beyond: Watch the primary metric, but don’t act on it until LaunchDarkly indicates you have enough data.
To learn how to read results, read Analyzing experiments.
Updating running experiments
You may find you need to make changes to a running experiment. Some changes are safe, while others can invalidate your experiment results. LaunchDarkly provides safeguards and recommendations so you can make updates with confidence.
Here are a few common scenarios:
- Ramping up traffic: You may want to increase the traffic in your experiment if you are not getting enough signal to make a decision.
- Stopping a test early: You may see definitive results earlier than you expected, and want to ship the winning variation early.
What’s next
- Reading and interpreting results
- Starting and stopping experiments
- Experiment health checks and SRM
- Holdouts: Running multiple experiments without contamination
- Mutually exclusive experiments: Preventing users from being assigned to more than one experiment simultaneously
- Warehouse-native metrics: Running experiments off your warehouse data
If you get stuck
- You don’t see events on the live events page: Check the SDK key matches the environment you’re viewing, confirm the SDK is initialized, and confirm there’s network connectivity to LaunchDarkly. To learn more, read Viewing incoming events.
- An SRM warning appeared: This usually means the audience changed mid-experiment, the randomization unit doesn’t match the context kind in code, or there’s a flag targeting overlap with another experiment. To learn more, read Experiment health checks.
- Your metric is flat, but you expected movement: Most often, the sample is too small to detect the effect size you expected, the effect is concentrated in a segment you’re not isolating, or the metric isn’t measuring what you thought. To learn more, read Experiment sizing.
- There are context kind mismatch errors: The randomization unit in the experiment doesn’t match the context kind the SDK is passing. To learn more, read Randomization units.
For additional help, open a Support ticket.